Google は2026年5月5日(現地時間)、オープンモデル「Gemma 4」ファミリー向けに「マルチトークン予測 (MTP) ドラフター」を公開したことを発表しました。
Hugging Face や Ollama など主要な推論フレームワークですでに利用可能となっており、出力品質を維持したまま推論時の待ち時間を最大 3 倍短縮できます。
MTP ドラフターとは
Gemma 4 の MTP ドラフターは、「Speculative Decoding」と呼ばれる手法を採用しています。
これは軽量な「ドラフターモデル」が複数のトークンを先読み予測し、大型の「ターゲットモデル」がその予測をまとめて検証する仕組みです。
ターゲットモデルが最終的な検証を担うため、出力品質は従来と変わりません。
対応モデルと速度向上の幅
MTP ドラフターは Gemma 4 全ファミリーに対応しています。
- 31B Dense:PC やワークステーションでの利用を想定したフルサイズモデル
- 26B MoE:混合エキスパート(Mixture of Experts)アーキテクチャを採用した大規模モデル
- E2B / E4B:Android スマートフォンなどエッジデバイス向けの軽量モデル
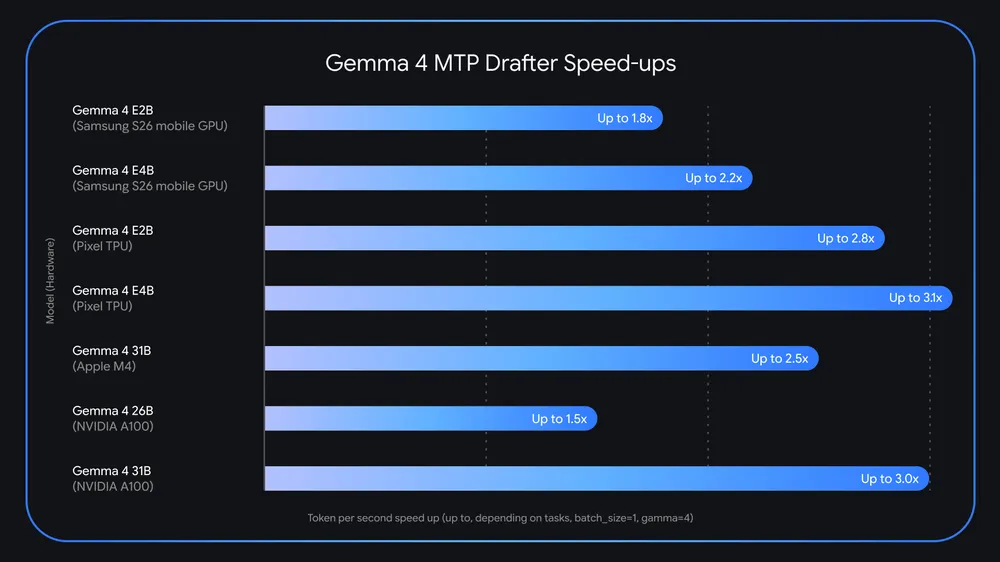
NVIDIA RTX PRO 6000 での実測では、Gemma 4 26B が標準推論と比較して約 2 倍のトークン毎秒 (tokens/second)を達成しています。
Apple Silicon 環境では最大約 2.2 倍のスピードアップが確認されています。
全体として、LiteRT-LM、MLX、Hugging Face Transformers、vLLM などの推論フレームワーク上でのテストでは最大 3 倍のスピードアップが報告されています。
PC やスマートフォンへの実質的なメリット
このアップデートにより、ユーザーは同じハードウェアでより速いレスポンスを得られるようになります。
PC 環境では、26B・31B といった大型モデルをローカルで動かす際の体感的な応答速度が改善され、コーディングアシスタントやエージェント的なワークフローのように、モデルが連続して思考・出力を繰り返すユースケースほど、レイテンシの削減効果が大きくなります。
Android デバイスについては、E2B・E4B モデルを搭載するアプリが同じ処理をより短い時間で完結できるようになるため、処理効率の向上に加えてバッテリー消費の抑制も見込まれます。
Google AI Edge Gallery(Android / iOS)でもテストが可能です。
利用方法
MTP ドラフターは、商用利用が可能な Apache 2.0 ライセンスのもとで公開されています。
開発者向けには Hugging Face や Ollama などの主要な推論フレームワークですでにサポートされており、既存の Gemma 4 導入環境であれば比較的スムーズに移行できます。
詳しい導入手順や技術的な詳細については、Google が公開している公式ドキュメントおよび技術解説記事にまとめられています。
まとめ
Gemma 4 の MTP ドラフターは、モデルの精度や品質に手を加えることなく推論速度を最大 3 倍に引き上げる手法です。
ローカル PC でオープンモデルを活用している開発者から、Android アプリのオンデバイス AI を扱うエンジニアまで、幅広い環境でそのまま活用できる点が大きな強みです。