Google は 2026 年 4 月 15 日 (現地時間) に、Gemini の新しいテキスト読み上げ (text-to-speech : TTS) モデルである Gemini 3.1 Flash TTS を発表しました。
現在、Google AI Studio および Gemini API、Vertex AI にてプレビュー版が利用可能となっており、Google Vids を通じて Workspace ユーザーへの展開も開始されています。
このモデルは、音声の品質と制御性が向上しており、200 種類以上の「オーディオタグ」と呼ばれる機能を用いて声の感情や話すペースを細かく指定できる点が特長です。
Gemini 3.1 Flash TTS の主な特長
Gemini 3.1 Flash TTS は、次世代の AI 音声生成を実現するために、品質と操作性の両面で大幅な強化が行われました。

高品質な音声と多言語対応
Gemini 3.1 Flash TTS は全体的な音声品質が向上し、Artificial Analysis の TTS リーダーボードでは Elo スコア 1,211 を記録しており、品質とコストのバランスが評価されています。
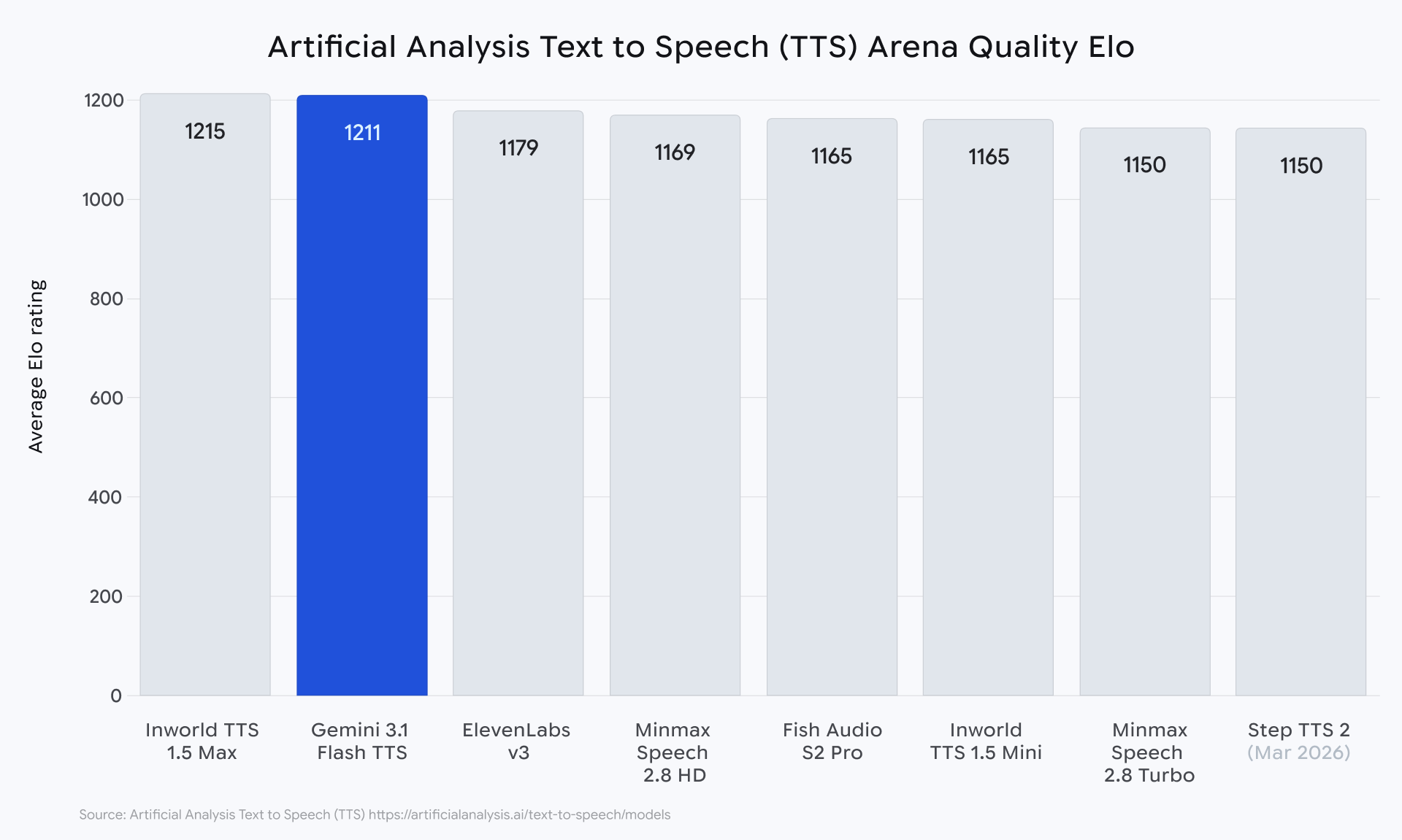
また、70 以上の言語と地域ごとのバリアントに対応し、ネイティブな複数話者の対話もサポートしています。
オーディオタグによる細かな音声制御
Gemini 3.1 Flash TTS モデルの大きな特長として、テキストの入力時にコマンドを埋め込むことで、声のスタイルやペース、表現を細かく指定できるオーディオタグを 200 種類以上サポートしています。
この機能を活用することで、自然言語の指示から声のトーンや間を変化させることができ、調整を終えた設定は Gemini API のコードとしてそのままエクスポートできるため、異なるプロジェクトやプラットフォーム間でも音声を維持しやすくなります。
SynthID による電子透かし機能
Gemini 3.1 Flash TTS で生成されたすべての音声には、SynthID による電子透かしが埋め込まれます。
この透かしは人間の耳には聞こえないように音声データへ直接統合されており、AI によって生成されたコンテンツであることを確実に検知し、誤情報の拡散を防ぐ目的で導入されています。
オーディオタグの仕組みと活用方法
オーディオタグは現在 200 種類以上がサポートされており、テキストの中に [xxx] を使ってタグを挿入することができます。
- [ペースのタグ] + 話すテキスト + [感情のタグ] + 話すテキスト + [間のタグ] + 話すテキスト
たとえば、[whispers](ささやき)や [laughs](笑い)といった感情的な表現や、[fast] や [short pause] などのペースの指示が使用できます。
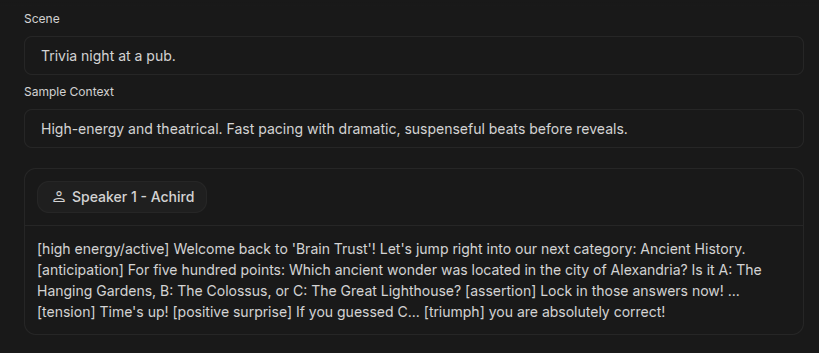
タグを連続して配置することはエラーの原因になるため、必ずテキストや句読点で区切る必要があります。また、タグ自体は英語で入力する必要がありますが、読み上げるテキストは日本語でも機能します。
想定される使い方
この機能は、アクセシビリティの向上やエンターテイメント、ビジネスなどのさまざまな場面での活用が想定されています。
たとえば、ゲームや映像作品の音声ガイドでは、場面に合わせて [enthusiasm] や [whispers] などのタグを使うことで、状況に合わせた音声を生成できます。
また、銀行や航空会社の自動音声案内では、[seriousness] と [positive] を切り替えたり、[slow] で重要な番号を読み上げたりするなど、音声応答システムの構築に適しています。
利用方法
Gemini 3.1 Flash TTS は、現在 Google AI Studio のプレイグラウンドにてプレビュー版としてテストでき、設定画面から新しい音声プレイグラウンドに用意された 30 種類のベース音声から選択して動作を確認できます。
企業向けには Google Cloud の Vertex AI でもプレビューが開始されており、Gemini API を通じてアプリケーションへの組み込みが可能です。
長文のコンテンツを作成する際は、Gemini 3.1 Flash-Lite を併用して自動的にテキストへタグ付けを行う応用も可能です。