Google は 2026 年 3 月 3 日(現地時間)、Gemini 3 シリーズの中で最速かつ最もコスト効率に優れた AI モデル「Gemini 3.1 Flash-Lite」を発表し、プレビュー版の提供を開始しました。
現在、開発者は Google AI Studio の Gemini API を通じて、エンタープライズ企業は Vertex AI を経由して利用可能になっています。
コストパフォーマンスと処理速度
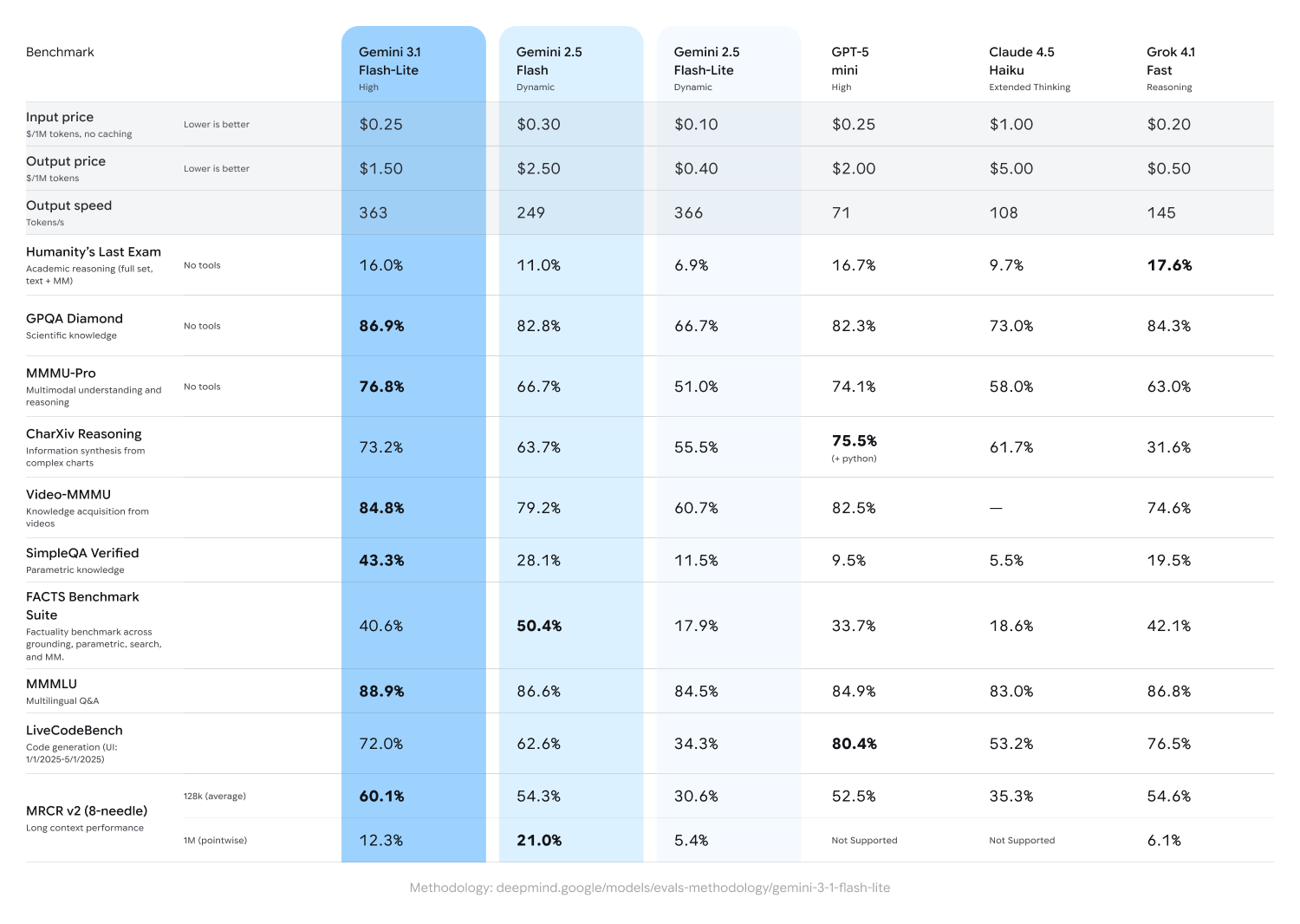
Gemini 3.1 Flash-Lite は、大規模なワークロードを処理する際のコスト効率とスピードが特長となっており、価格は入力 100 万トークンあたり 0.25 ドル、出力 100 万トークンあたり 1.50 ドルに設定され、上位モデルと比較して運用コストを抑えることができます。
また、処理速度は前世代の Gemini 2.5 Flash と比較すると、最初の回答が出力されるまでの時間(Time to First Answer Token)が 2.5 倍高速化し、全体的な出力スピードも 45% 向上しました。これだけの高速化を果たしながら、回答の品質は同等かそれ以上を維持しています。
高頻度で処理を行うワークロードや、リアルタイムの応答性が求められるアプリケーション開発において、実用的な選択肢になります。
各種ベンチマークテストにおいても、Arena.ai のリーダーボードで 1432 の Elo スコアを記録しています。さらに、推論やマルチモーダル理解においても同クラスのモデルを上回り、GPQA Diamond で 86.9%、MMMU Pro で 76.8% と、前世代の 2.5 Flash を上回るスコアとなっています。軽量化にとどまらず、ベースの精度も引き上げられています。
思考レベルによる柔軟なタスク制御
Gemini 3.1 Flash-Lite では、AI Studio および Vertex AI にて「思考レベル(thinking levels)」機能が標準で利用可能です。
これにより、モデルにタスクを処理させる際に「どれだけ深く推論させるか」を開発者側でコントロールできます。
大量の翻訳やコンテンツのモデレーションといったコストとスピード重視のタスクから、ユーザーインターフェースの生成や複雑な指示に従うような深い推論が必要なタスクまで、用途に応じて思考の深さを調整できるため、実際の運用においても柔軟に対応できます。
すでに早期アクセスを利用している企業からは、複雑な入力を上位モデル並みの精度で処理できる点や、指示に対する高い遵守性が評価されているとしています。
まとめ
今回の Gemini 3.1 Flash-Lite のプレビュー展開により、開発者は低コストかつ低遅延で、応答性の高い AI 機能をサービスに組み込めるようになりました。
処理速度と精度のバランスが優れているため、日々の開発ワークロードを効率化したい場合は、Google AI Studio などで実際に挙動を確認してみてください。