Google は 2026 年 1 月 27 日(現地時間)、AI モデル「Gemini 3 Flash」向けに、新しい視覚推論機能である「Agentic Vision」を発表しました。
この機能は、AI がただ画像を見るだけでなく、必要に応じて「コード実行」を行い、画像を拡大したり注釈を付けたりして詳細を確認できるというものです。
すでに Google AI Studio および Vertex AI の API で利用可能となっており、Gemini アプリ(思考モード)への展開も始まっています。
AI が「見る」だけでなく「調査する」
これまでの AI モデルは、提示された画像を「静的な一枚の絵」として全体をざっと処理するのが一般的でした。そのため、画像内の小さなシリアル番号や遠くの看板、密集したオブジェクトなど、細かい部分を見落としたり、推測で回答して間違ったりすることがありました。
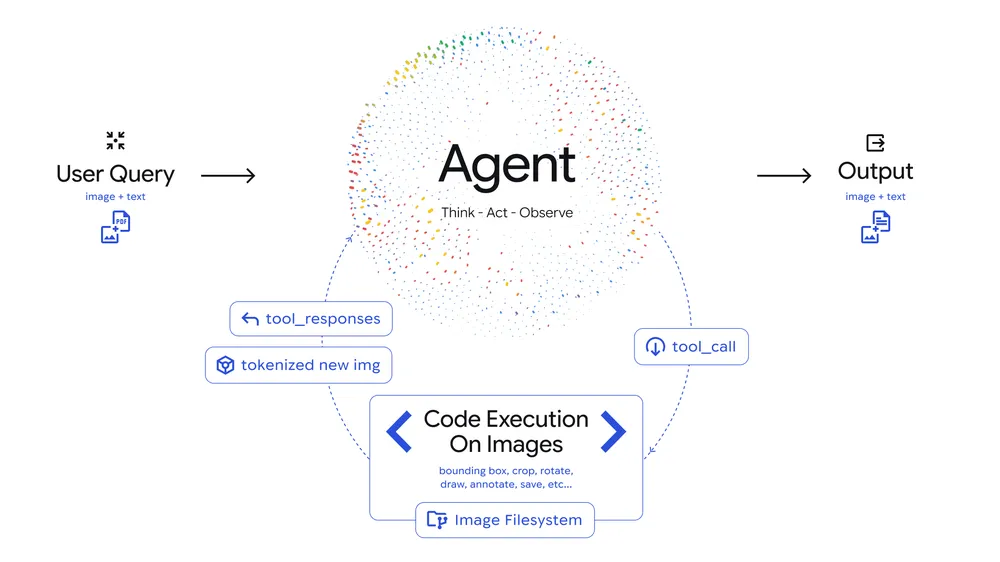
今回導入された「Agentic Vision」は、視覚(Vision)を単なる入力としてではなく、「Think(思考)、Act(行動)、Observe(観察)」というループによる「能動的な調査プロセス」として扱うことで、正確な答えを導き出します。
- Think(思考): ユーザーの質問と画像を分析し、どうすれば答えられるか計画を立てる
- Act(行動): Python コードを生成・実行し、画像を操作(切り抜き、回転、注釈付けなど)したり、計算を行ったりする
- Observe(観察): 操作後の画像を再度確認し、より鮮明なコンテキストを得てから回答を作成する
主な変更
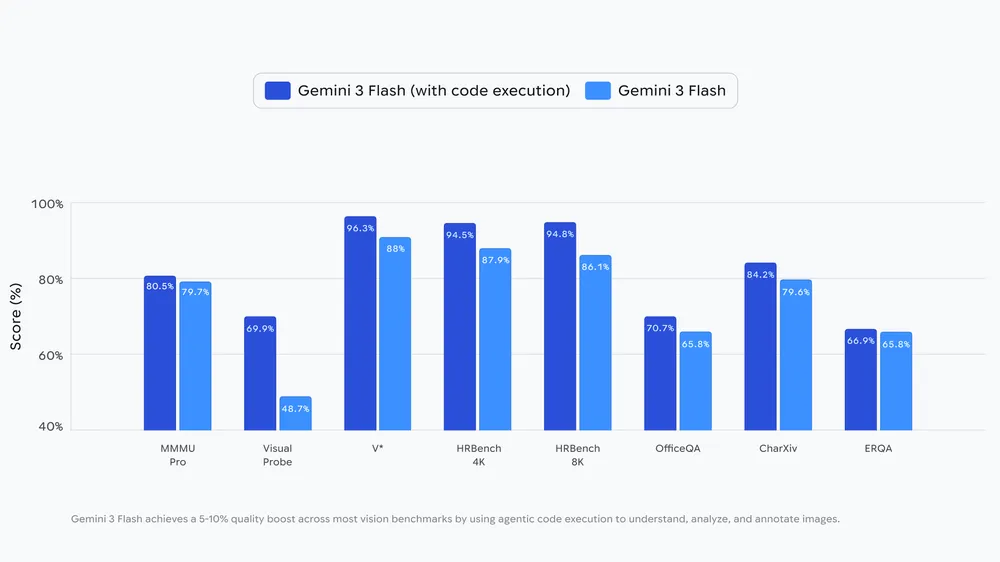
Google によると、この機能によって視覚ベンチマークの品質が 5〜10% 向上するとのことです。例えば、以下のようなケースで威力を発揮するとしています。
細かい部分のズームと確認
Gemini 3 Flash は、画像内に詳細な確認が必要な箇所(建物の図面の細部や、小さな文字など)があると判断した場合、自動的にその部分をズーム(切り抜き)して再確認します。

これにより、高解像度の図面チェックなどで、推測ではなく事実に基づいた判断が可能になります。
数のカウントと注釈(指の本数など)
AI にとって「画像内の物体を数える」のは意外と難しいタスクです。 Agentic Vision では、例えば「手の指を数えて」と頼むと、Python コードを使って検出した指一本一本に「バウンディングボックス(枠)」と「番号」を描き込みます。
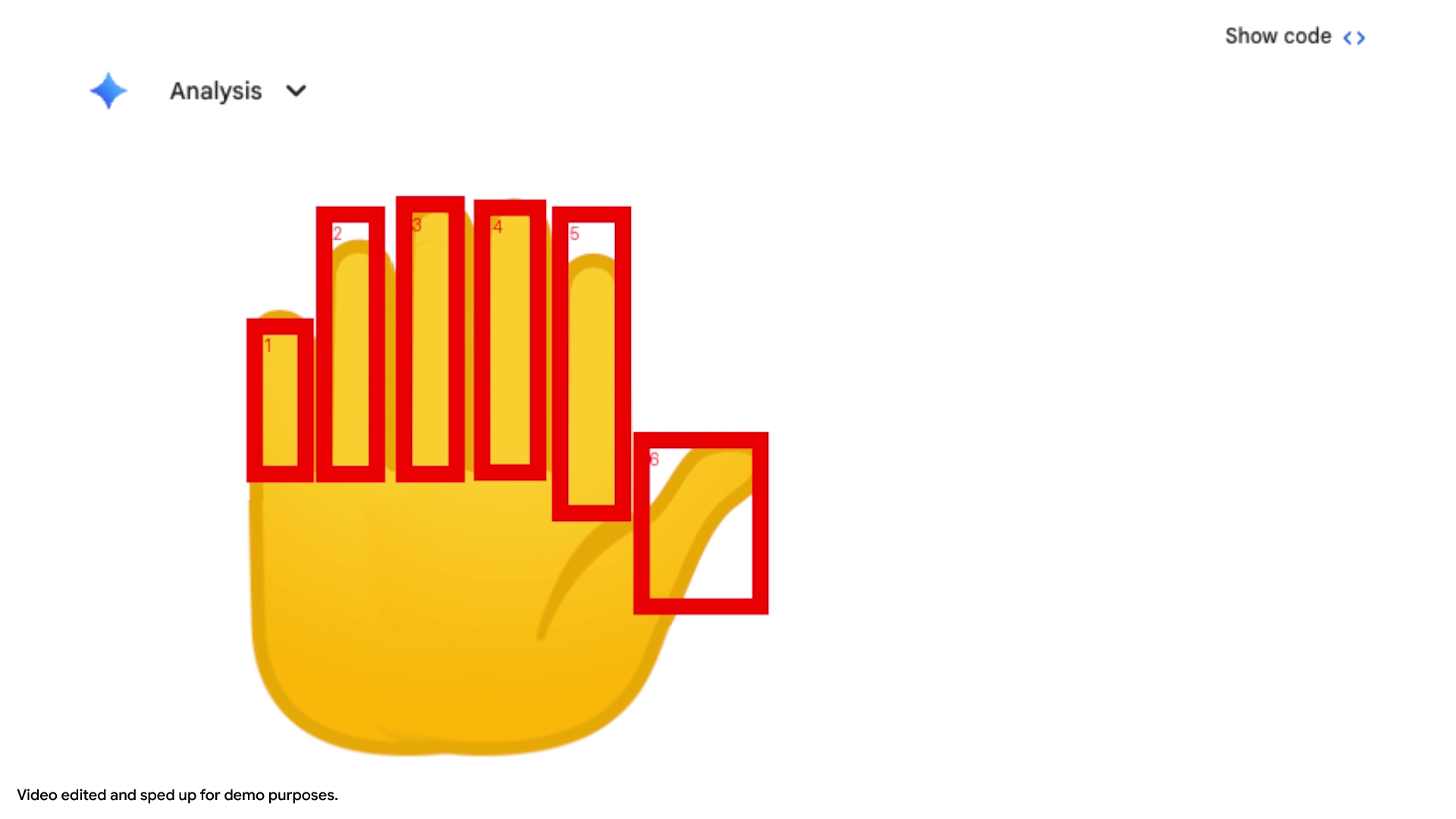
この「視覚的なメモ(Visual scratchpad)」を作成することで、数え間違い(ハルシネーション)を防ぎ、正確なカウントを実現します。
グラフ作成と正確な計算
画像内の複雑な表データを読み取る際も、単にテキストとして認識するだけでなく、Python 環境で計算を行ったり、Matplotlib などのライブラリを使って正確なグラフとして描画したりすることが可能になります。
確率的な推測ではなく、計算に基づいた結果が出せる点が大きな強みです。
利用方法と今後の展開
この機能は、開発者向けには Google AI Studio および Vertex AI にて、API を通じて本日から利用可能です。
一般ユーザー向けには、Gemini アプリのモデル選択で「思考モード」モデルを選ぶことで、順次利用可能になりつつあります。
現時点では、画像の「ズーム(拡大)」機能は AI が自動的(暗黙的)に判断して行いますが、画像の回転やグラフ描画などは、プロンプトで具体的に指示する必要がある場合があるようです。
Google は今後、Web 検索や逆画像検索などのツールも統合し、さらに機能強化をしていくとしています。